
Mapping political contribution networks
[build query] [tutorial] [news blog]
What is it?
Unfluence is a web program that generates interactive network maps of state level political contribution data. Circles indicate candidates running for a political office. Green circles represent their contributors. Gray arrows (a.k.a "links" or "edges") indicate the size and direction of contributions (thicker arrows mean more $.) The size of the circles ("nodes" or "vertices") is proportional to the total amount given or received. Modifying the query selects different groups of candidates and ranges of edges to be included when building the network.
Clicking on nodes gives access to additional summary information about candidates in an info bubble.
About the unfluence project
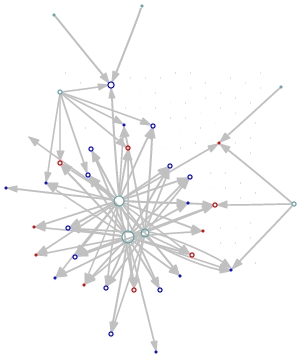 We are excited about the possibility of creating a clean and intuitive way to
explore political contribution data. This project was built to test the
idea of visualizing candidates and their contributors as a browseable
network. A sort of quick visual data mining tool for transparency that
everyday people can use. Putting the data in a network form also makes it
possible to compare patterns of giving across various states and interest
groups.
We are excited about the possibility of creating a clean and intuitive way to
explore political contribution data. This project was built to test the
idea of visualizing candidates and their contributors as a browseable
network. A sort of quick visual data mining tool for transparency that
everyday people can use. Putting the data in a network form also makes it
possible to compare patterns of giving across various states and interest
groups.
For example, compare a network for Maine - a state with publicly funded
campaigns - with Oregon
Or see which California Senators are receiving donations from Electric Utilities
in 2006, compared to 2004
How does it work?
A query is generated from your search settings and sent to National Institute on Money in State Politics' API which looks in their databases and returns a list of matching candidates as an xml file. For each candidate we get a list of the top contributors, and discard any with contributions below the value threshold you set. This donor-recipient information is formatted into a network and passed to a program called GraphViz that computes positions for the nodes and draws it (with help from ImageMagik). The image is passed back to you. When you click on a node, we send queries to NIMSP and Project VoteSmart to check if there is information available (this requires some hacked scraping and matching code) for that candidate, and include the links in the info bubble. The visual effects are provided by script.aculo.us.
Where do the data come from?
The state-level contribution data are compiled by the National Institute on Money in State Politics, a non-profit:
"...dedicated to accurate, comprehensive and unbiased documentation and research on campaign finance at the state level. The Institute develops searchable databases, makes them available to the public online, and analyzes the information to determine the role campaign money plays in public policy debates in the states."
"The Institute receives its data in either electronic or paper files from the state disclosure agencies with which candidates must file their campaign finance reports. The Institute collects the information for all state-level candidates in the primary and general elections and then puts it into a database." (more about data)Various portions of the database are then made accessible via an API so that programs like ours can use it.
We also provide links to data available from the VoteSmart site for many incumbents in recent years. They provide very useful data like biographical summaries, surveys of candidates' positions on current issues, ratings by various interest groups, and voting records. These data are not available for candidates from less recent years, and we may not always correctly match up to their data.
How clean are the data?
Actually, that is a good question for NIMSP. There are definitely some funny nodes in there, but overall it seems pretty good. But matching up names (the "entity resolution problem") is an interesting and difficult task. You want to be able match "ACLU" with "American Civil Liberties Union" without confusing "John Smith" who lives in Nebraska with "John Smith" in NY. There are bound to be some errors though, and sometimes the picture makes them easier to find.
Why isn't there information available for every node?
Well, there are a number of reasons. Complete info on the contributors is not released publicly by NIMSP to protect donors' addresses from mailing list webscrapers. Many of the candidates do not appear in the VoteSmart databases because they never actually held office. Or our quick-and-dirty matching code was unable to correctly match the candidates across the databases.
Should I trust the results?
Maybe. This is really the alpha version of a proof-of-concept. There are definitely bugs in our code. Consider anything you find here an illustrative example, and go back through the data before you make any strong conclusions.
What are the next steps for the project?
We would like to be able to build other kinds of networks, make the architecture stronger, and expand it to include data for the US House and the US Senate from the FEC databases.
Can I give you guys money to develop this further or hire you?
You bet. We are broke starving programmers. We are interested in building a much more general tool that could be applied to other data sets (FEC contributions, ballot measures, congressional voting, etc.) and generally developing open source tools for data integration and visualization. Especially for things like government transparency and progressive causes. It would also be great to design and coordinates systems for sharing data among projects so that these kinds of things can be built more effectively and with less hacking.
Can I have your source code?
Yes, but give us a few weeks to clean it up.
Acknowledgments
- The folks at NIMSP for making their data available and being helpful and enthusiastic.
- primate.net for server space.
- All the great open source authors of programs that make projects like this possible.
- Our girlfriends for putting up with late night coding binges